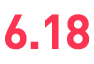下载学堂APP缓存视频离线看
下载学堂APP缓存视频离线看
- 畅销套餐
- 精选套餐
- 人气套餐
- 尊享套餐
- 高薪套餐










- 课程介绍
- 课程大纲
适合人群:
帮助Python初级程序员提高项目实战能力 帮助想从事Python网络爬虫开发的人员深入掌握并理解网页抓取的方法
你将会学到:
提高项目实战能力;帮助深入掌握并理解网页抓取的方法
- 我们将通过网页爬虫的开发,在实战过程中带大家快速掌握爬取网页的原理
课程简介:
一、介绍
网络爬虫程序是一个沿着链接漫游web文档集合的程序。它一般驻留在服务器上,通过给定的一些url,利用http等标准协议读取相应文档,然后以文档中包括的所有未访问过的url作为新的起点,继续进行漫游,直到没有满足条件的新url为止。requests是唯一的一个非转基因的python http库,人类可以安全享用。lxml是python的一个解析库,支持html和xml的解析,支持xpath解析方式,而且解析效率非常高。这门课程将应用python、requests、lxml、sqlalchemy、multiprocessing等技术开发一个简单的网页爬虫。我们将通过网页爬虫的开发,在实战过程中带大家快速掌握爬取网页的原理。
二、章节
第1章: 知识点介绍
1-1:网络爬虫介绍
1-2:http介绍
1-3:爬虫技术架构介绍
第2章: 开发环境准备
2-1:安装python语言环境
2-2:安装pycharm编辑器
2-3:安装mysql数据库
2-4:安装第三方依赖包
第3章: 编写网页爬虫
3-1:案例需求分析
3-2:数据模型设计
3-3:编写单进程爬虫
3-4:编写多进程爬虫
3-5:提取网页节点数据
3-6:保存网页节点数据
第4章: 课程总结
4-1:课程总结
开发工具:
Python3.6、Pycharm、MySQL
课程大纲-Python爬虫项目实战
第1章知识点介绍(28分钟3节)
第2章开发环境准备(48分钟4节)
第3章编写网页爬虫(2小时43分钟6节)
第4章课程总结(3分钟1节)
“RustGoPy”老师的其他课程更多+