Bayesian Transformer自编码模型BERT培训课程片段3:BERT输入内容Word Embeddings三大步骤及其内幕工作流程详解


打开微信、微博、QQ
扫描二维码,即可分享


公开笔记对他人可见,有机会被管理员评为“优质笔记”
{{ noteEditor.content.length }}/2000

BERT源码课程片段3:BERT模型Pre-Training多头注意力机制Multi-head Attention完整源码实现
本视频深入探讨了基于Transformer的神经网络架构,尤其关注了BERT模型。讲解包括模型的encoder堆栈、输入输出处理、内部向量维度和注意力头的设置。介绍了多头注意力机制的重要性和如何实现token、位置和句段嵌入的细节,以及如何优化参数初始化。同时,还涉及了遮蔽、归一化和dropout等关键技术点。该内容适合对深度学习、NLP和Transformer架构有兴趣或工作经验的技术人员。
12:083278BERT源码课程片段6:BERT模型Pre-Training中的MLM及NSP源码实现及最佳实践
视频内容围继承BERT训练任务的实现和原理解析,包括Next Sentence Prediction与Mask Language Model两大主要任务。解释了CLS token在确定句子间关系的作用,并展示了hidden vector的生成和处理,涉及到分类任务的逻辑一致性。提到了模型训练过程中的技术细节,如checkpoint的设置,以及如何在训练失败时基于现有进度恢复训练。最后,介绍了BERT模型微调(fine-tuning)的概念及其在特定应用场景下的重要性,如阅读理解任务。
08:192594贝叶斯Bayesian Transformer课程片段6:Bayesian Transformer这种新型思考模型在学术和工业界的意义是什么,为什么说Trans
本次内容聚焦在提高Transformer模型的多头注意力机制多样性上,探讨不同层之间的注意力集成的方法和优化技巧。指出每个多头相当于样例,存在冗余风附,强调通过正则化和特征稀疏化增加模型多样性。介绍了如何利用预训练嵌入提高模型性能,以及Dropout作为一种正则化手段。同时,提到了在不同模型阶段参数共享和大规模参数网络的训练技术。对于感兴趣于模型结构优化和深入理解Transformer机制的观众,这些信息特别有价值。
06:052523自然语言处理实战及应用
课程内容聚焦于自然语言处理(NLP)的基硬技术和应用实践。开始部分介绍自然语言处理的综述,探讨基本技术和核心应用。接下来,深入文本处理技能,比如中文分词和文本数据预处理,涉及词频统计等。进一步探讨词向量的创建,从最初的one-hot编码到更高级的离散和分布式表示方法,包括TF-IDF和神经网络语言模型。之后,介绍关键词提取技术及其在文本检索和分类中的应用,例如利用朴素贝叶斯算法和n-gram语言模型对中文文本进行分类和新闻文本的词汇预测,最终实现基于机器学习算法的自然语言处理任务。
07:354554自然语言处理实战及进阶应用
视频内容围绕深度学习在自然语言处理(NLP)领域的实用应用及其进阶技巧展开讨论,特别是使用PyTorch框架进行模型的构建和训练。介绍了如何安装PyTorch及其使用数据集(Dataset)和数据加载器(DataLoader)的方法。进一步深入讨论了基于PyTorch的视觉和文本处理API,如TorchVision和TorchText。视频进阶部分讲述从传统机器学习到使用FastText进行文本分类的过渡,解释了词向量表示以及如何将模型应用于中文文本分类任务。此外,还扩展到了使用文本卷积神经网络(CNN)和循环神经网络(RNN)以及它们的结合来提高文本分类性能。
05:054345Bayesian Transformer自编码模型BERT培训课程片段6:从Output结果向量和矩阵相乘的角度来解析BERT整个Encoder Stack的功
本视频深入探讨了BERT模型架构与其内部工作原理,重点分析了由多层Encoder构成的网络结构,并通过运用多头注意力机制、残巜网络、前馈神经网络等组件,实现对输入数据的高效处理和信息表达。视频进一步解释了如何通过隐藏向量与矩阵乘法结合Softmax等算法,进行诸如文本分类、命名实体识别等下游任务。内容深入而详细,适合有机器学习及自然语言处理背景的研究者或开发者,尤其对于寻求理解和应用BERT模型相关技术的专业人员来说,提供了具体的指导和见解。
05:202507爆炸爆炸,AI的效果爆了
00:1015.8万搭建私人助理大模型需要什么环境?
讲者在视频中指导如何搭建Streamlit环境,突出点在于使用Python语言进行开发,推荐使用Anaconda进行一站式环境配置,易于管理包和编辑器。强调Streamlit的安装非常简单,仅需使用pip进行安装无需复杂配置。此外,还推荐了几种集成开发环境(IDE)如PyCharm、VS Code,依据个人喜好选择。这项内容适合于已经对Python有一定了解的人群,尤其是有兴趣在数据科学和Web应用快速开发领域进步的开发人员。
01:434.4万
 114课时
114课时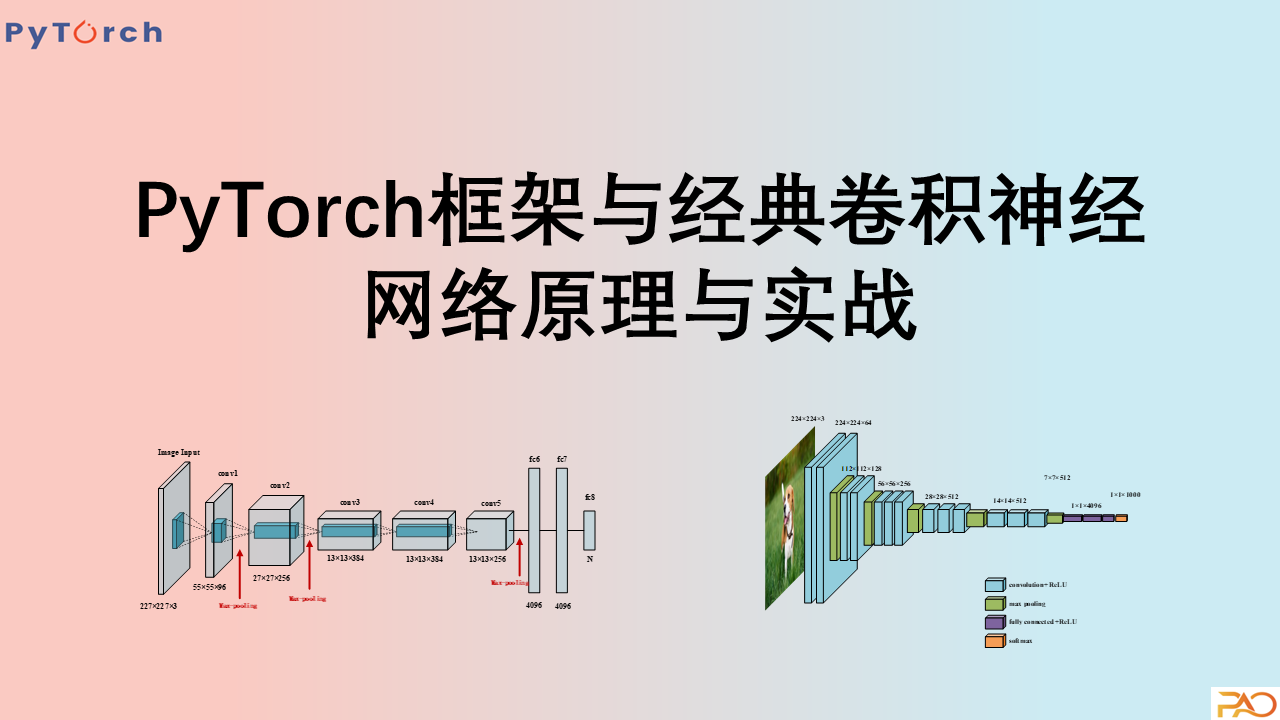 117课时
117课时 36课时
36课时 37课时
37课时 22课时
22课时 65课时
65课时 19课时
19课时 18课时
18课时